

Implementing a Data Lakehouse Architecture in AWS — Part 1 of 4
The Data Lakehouse is a new architecture that combines the flexibility, low cost, and scale of data lakes with the data warehouses' power.

Introduction
Numerous applications in today’s world accumulate significant amounts of data to build insight and knowledge. Adding value and improving functionality is essential, but at what cost? A critical factor in the "Big Data" era’s arrival is vastly decreasing the data storage cost while increasing available computing power over the cloud.
Since the first release of Apache Hadoop in 2008, the framework’s extensibility has allowed it to grow and improve its capabilities of collecting, storing, analyzing, and managing multiple sets of data. Multiple “Big Data” projects have been added to the Data Architect’s toolbox to create more powerful and intelligent solutions. One of these newer Data Architectures is the so-called Data Lakehouse.
What is a Data Lakehouse?
The Data Lakehouse is a new form of data architecture that combines the positive aspects of Data Lakes and Data Warehouses. Data Lakes' advantages range from flexibility to low cost and scale. When paired with the powerful data management and ACID transactionality of Data Warehouses, this allows for business intelligence, analytics, and machine learning on all data in a fast and agile way.
But it doesn’t end there. A powerful Data Lakehouse will connect the Data Lake, the Data Warehouse, and the purpose-built databases and services into a single structure. This also includes a unified Governance approach, tools, and strategies to move data inside-out and outside-in with minimal effort and cost.
The Data Lakehouse is enabled by a new, open system design that implements similar data structures and data management features to those found in a Data Warehouse directly onto the kind of low-cost storage used for Data Lakes. Merging them into a single system means that data teams can move faster while using data without accessing multiple systems. Data Lakehouses also ensure that teams have the most complete and up-to-date data for data science, machine learning, and business analytics projects.
In this Article Series, we will explore how to embrace Big Data Architecture and implement it in AWS.
Key Technology Enabling the Data Lakehouse
The implementation of Data Lakehouse Architecture in AWS has a simple storage system, or S3, at its core, providing object storage to build a Data Lake. Around the Data Lake, you can add other components such as:
“Big Data” processing with Elastic Map Reduce;
Relational Databases with Relational Database Service, in special Amazon Aurora;
Non-Relational Databases such as Amazon DynamoDB;
Machine Learning for business analysis with Amazon SageMaker;
Data Warehousing with Amazon Redshift;
Log Analytics powered by OpenSearch.
As you may guess, connecting all of the components above as a Data Lakehouse requires setting up the Data Stores, Databases and Services as well as allowing fast and easy data transfer from the services utilized to the Data Lake (data movement outside-in), ingesting data from the Data Lake to the purpose-built databases and services (data movement inside-out) and also moving data from one purpose-built datastore to another (data movement around-the-perimeter).
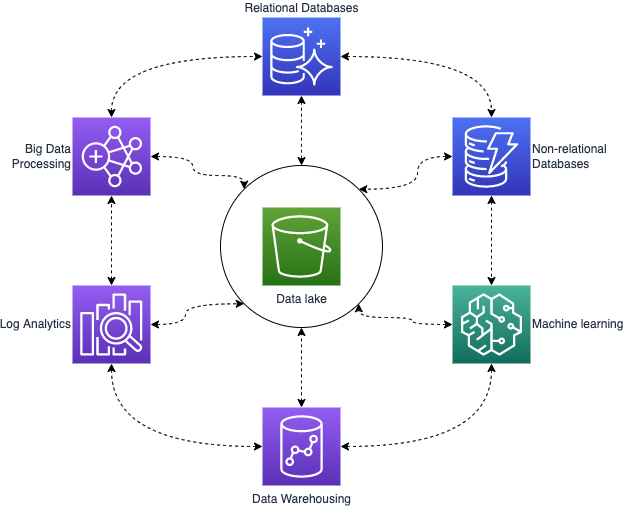 Lakehouse data movements
Lakehouse data movements
To get the most from their Data Lakes and these purpose-built stores, customers need to easily move data between these systems. For instance, clickstream data from web applications can be collected directly in a Data Lake. A portion of that data can be moved out to a Data Warehouse for daily reporting. We think of this concept as an inside-out data movement.
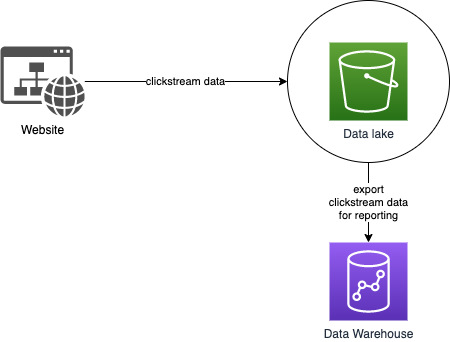 Outside-in data movement
Outside-in data movement
Finally, in other situations, customers want to move data from one purpose-built data store to another: around the perimeter. For example, they may copy the product catalog data stored in their database to their search service to make it easier to look through their product catalog and offload the search queries from the database.
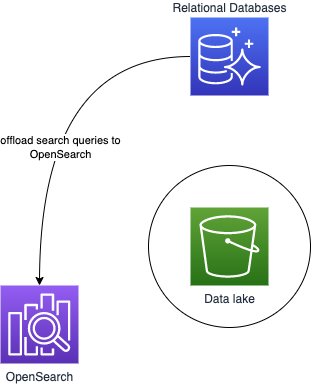 Around-the-perimeter data movement
Around-the-perimeter data movement
As data in the Data Lake and other data stores increases, the Data Gravity also grows, becoming more challenging to move the data in any direction. A key service to make all data movement agile while the data gravity grows is Amazon Kinesis. In a nutshell, Amazon Kinesis allows you to process and analyze data as it presents itself, responding to it quickly in real time with no delay.
Let’s dive deeper into how this process works. Kinesis has three different services: Kinesis Data Stream, Kinesis Data Firehose, and Kinesis Data Analytics.
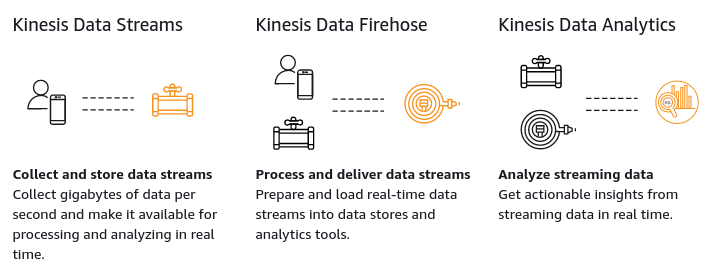
Kinesis is a serverless service that is resilient, durable, reliable, and available by default. With it, you can develop applications that ingest streams of data and react to it in real time, allowing you to build value from the stream’s data very fast, with minimal operational overhead.
A Kinesis Data Stream is best served for quick and continuous intake of data, which can include social media, application logs, market data feeds, or IT infrastructure log data. Each stream is composed of a set of shards, which are the read-and-write capacity units in Kinesis. One shard provides a stream with the capacity to read up to 1 MB of data per second, and write at a rate of 2 MB per second. When creating a Kinesis stream, you must specify the number of shards provisioned for that stream as well as a few other parameters. If the data volume being written to the stream increases, you can add more shards to scale up the stream without any downtime.
To use Kinesis Data Streams, a typical scenario is to have producers push the data straight into the software systems that write Kinesis’s stream data. A producer could be an EC2 instance, a mobile app, an on‑premise server, or an IoT device. On the other hand, there are consumers that retrieve records from Data Streams and process them accordingly. A consumer might be an application running on an EC2 instance or an AWS Lambda function. If the consumer is on an Amazon EC2 instance, you can run it within an Auto-Scaling group to scale it up. In this case, you only pay for the shards allocated per hour.
It is possible to have more than one application type processing the same data. An effortless way to develop consumer applications is to use AWS Lambda, which will scale up or down automatically since it lets you run the consumer application’s code without providing or managing servers.
Kinesis Data Streams allow preserving the client ordering of your data, and it’s guaranteed to be received by the consumer in the same order the producer sent the data. It is also possible to process the data in parallel, so you can also consume the same data stream in parallel to multiple applications at one time. For example, you could ingest application log data while the first consumer looks for specific keywords, and have the second consumer use the same data to generate performance insights. This characteristic allows for decoupling the collection and processing of your data while providing a persistent buffer for it. Also, processing the data at your own desired rate depends on your needs, so there is no need to worry about some processes being directly reliant on others.
Also, Kinesis Data Streams make it easy to ingest and store streaming data, while making sure your data is durable and available, which is usually less than 1 second after writing it to the stream. For security purposes, it is possible to use server-side encryption to secure your data to meet any compliance requirements.
Some use cases for big data streaming are:
Fraud detection on e-commerce platforms (monitoring logs in real-time);
Analytics for mobile phone or web apps with millions of users by ingesting the clickstream;
Tracking and responding in real-time to a large fleet of IoT devices emitting sensor data;
Performing sentiment analysis of social media postings in real time.
All of the above use cases have something in common, which is the need to process many small messages generated in a wide variety of sources in near-real-time. The messages need to be ingested, stored, and made available to different applications. Also, it needs to be done in a reliable, secure, and scalable manner. However, you don’t want to keep multiple copies of this data, as one copy for each application would suffice.
Overall, Kinesis will store the streamed data for a limited amount of time. By default, it will hold any sequence of events for 24 hours, but the retention period can extend up to 7 days. You will need to write the processed results to a persistent store, such as Amazon S3, DynamoDB, or Redshift.
Problem to Solve
In this article, we want to illustrate how easy it is to start feeding a Data Lake built on top of Amazon S3, based on streaming data. An application may generate events that we might want to store to build insights and knowledge while creating value from the derived data.
Roadmap
The first initial thought to implement feeding a Data Lake based on real-time streaming data could be to implement a Kinesis consumer to store the consumed events into S3 using the AWS API or SDK. However, there is a more elegant alternative.
We will use a Kinesis Data Firehose Delivery Stream to feed the data into the S3 seamlessly.
Journey
Among the several ways to send message streams to Kinesis, we will use a producer developed in Python with the library Boto3 to establish communication and message delivery. The message producer will use the library Faker, widely used for creating random fake data, and a parameter to define the number of messages created and sent to Kinesis. We will use Terraform to automate the creation of necessary resources and ensure version control.
Below we will list each used resource and its role in that context:
Data Producer — Python program to generate data;
Kinesis Data Streams — Will receive the generated messages;
Kinesis Data Firehose — To deliver the received message, converted into parquet file;
Amazon S3 — The bucket used to store the generated data;
Glue Data Catalog — We’ll use the Glue Data Catalog to have a unified metastore;
Amazon Athena — Used to query the data stored in the S3 bucket.
The diagram below illustrates the proposed solution’s architecture design.

Proposed Environment
AWS Service Creation
To start the deployment, we will validate the infrastructure code developed with Terraform. If you don’t have Terraform installed, here we’ll see two approaches, installing from the repository as well as downloading the standalone version.
# Installing from repository
$ curl -fsSL https://apt.releases.hashicorp.com/gpg | sudo apt-key add -
$ sudo apt-add-repository "deb [arch=amd64] https://apt.releases.hashicorp.com $(lsb_release -cs) main"
$ sudo apt-get update && sudo apt-get install terraform
$ terraform -version
Terraform v1.1.4
on linux_amd64
# Standalone version
$ curl -o terraform.zip https://releases.hashicorp.com/terraform/1.1.4/terraform_1.1.4_linux_amd64.zip && unzip terraform.zip
$ ./terraform -version
Terraform v1.1.4
on linux_amd64
Now, we will need to initialize Terraform by running terraform init. Terraform will generate a directory named .terraform and download each module source declared in the main.tf file.
Following the best practices, always run the command terraform plan -out=kinesis-stack-plan to review the output before starting, creating or changing existing resources.
After getting the plan validated, it’s possible to safely apply the changes by running terraform apply “kinesis-stack-plan”. Terraform will do one last validation step and prompt confirmation before applying.
In the video embedded below, you will see the whole process of creating the environment.
Data Producer
The code snippet below shows how the data dictionary will be created randomly and then converted into JSON. We will need to convert the dictionary into JSON to place the data into the Kinesis Data Stream.
# Function to produce data
def data_producer():
fake_data = Faker()
time_now = datetime.datetime.now()
time_now_string = time_now.isoformat()
record_data = {
'uuid': str(uuid.uuid4()),
'event_date': time_now_string,
'status': fake_data.random_element(elements=("Active", "Inactive", "Canceled")),
'name': fake_data.first_name(),
'last_name': fake_data.last_name(),
'email': fake_data.email(),
'phone': random.randint(900000000, 999999999)
}
return record_data
def data_sender(max_record):
record_count = 0
# Create the streaming data and send it to our Kinesis Data Stream
while record_count < max_record:
data = json.dumps(data_producer())
print(data)
kinesis.put_record(
StreamName="kinesis-rd-stream",
Data=data,
PartitionKey="partitionkey")
record_count += 1
Now is the time to start generating data, setting up the python virtual environment, and installing dependencies. Making the environment isolated will prevent breaking any other python library that could be in use.
# Library setup
$ python3 -m venv env
$ source env/bin/activate
$(env) pip3 install -r requirements.txt
Using the data producer script, we will start sending 10 records to our Kinesis service.
$(env) python3 data-producer.py --amount 10
2022-02-02T15:17:07 - INFO - Started data generation.
{"uuid": "c4885146-33f7-481d-8cc6-e894b6f33d7f", "event_date": "2022-02-02T15:17:07.618098", "status": "Inactive", "name": "Alicia", "last_name": "Olson", "email": "rwright@example.net", "phone": 910322509}
{"uuid": "df8dd9d8-ce33-4c93-9db2-93df224f8775", "event_date": "2022-02-02T15:17:07.626915", "status": "Active", "name": "Jose", "last_name": "Saunders", "email": "wileytimothy@example.com", "phone": 943771860}
{"uuid": "3c6ccb3c-50b2-43e7-8b77-5435e8a1c063", "event_date": "2022-02-02T15:17:07.637195", "status": "Canceled", "name": "David", "last_name": "Vega", "email": "pjones@example.com", "phone": 909231551}
{"uuid": "2e09d7d0-1c85-4d5d-bc9b-57287fc6563e", "event_date": "2022-02-02T15:17:07.644889", "status": "Active", "name": "Kathleen", "last_name": "Davis", "email": "xnash@example.com", "phone": 927204248}
{"uuid": "276d9ff1-643f-4c0d-a155-1a4f8dbc6f35", "event_date": "2022-02-02T15:17:07.652761", "status": "Inactive", "name": "Samuel", "last_name": "Jones", "email": "millercory@example.com", "phone": 965026462}
{"uuid": "c39535d9-5c29-4438-a7dc-a184fccea498", "event_date": "2022-02-02T15:17:07.660919", "status": "Canceled", "name": "Donna", "last_name": "Myers", "email": "kanejudy@example.org", "phone": 948655060}
{"uuid": "1eff13d4-a0d7-4a62-b1ee-0754dadab4c1", "event_date": "2022-02-02T15:17:07.670282", "status": "Canceled", "name": "Luke", "last_name": "Kelley", "email": "hayesyvonne@example.com", "phone": 992485746}
{"uuid": "d189692d-3d96-4723-b683-2e82ac8a0bcc", "event_date": "2022-02-02T15:17:07.678218", "status": "Inactive", "name": "Tina", "last_name": "Richards", "email": "smithjon@example.net", "phone": 960778676}
{"uuid": "80da5d2e-593f-4ac1-a91e-0f45618085ac", "event_date": "2022-02-02T15:17:07.686308", "status": "Canceled", "name": "John", "last_name": "Fox", "email": "michael33@example.com", "phone": 907743911}
{"uuid": "764cfbeb-7404-4388-9292-abc8eaf634cc", "event_date": "2022-02-02T15:17:07.694925", "status": "Active", "name": "Jeffrey", "last_name": "Willis", "email": "rick01@example.org", "phone": 975060130}
2022-02-02T15:17:07 - INFO - 10 messages delivered to Kinesis.
An important point to be aware of is that it will take a couple of seconds to see the generated data arriving in the Kinesis.
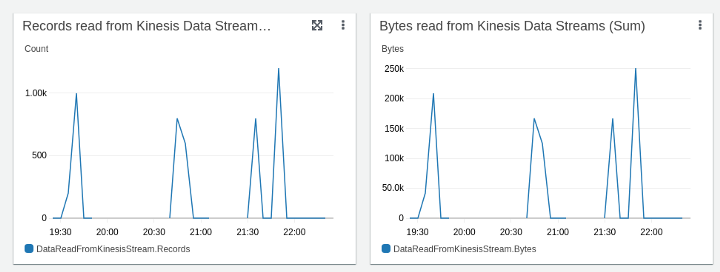
Looking at the Kinesis Data Stream’s statistics graph below, it is possible to follow the rate of received data and how it is processed.

The same is possible in the graph below with Kinesis Data Firehose statistics.
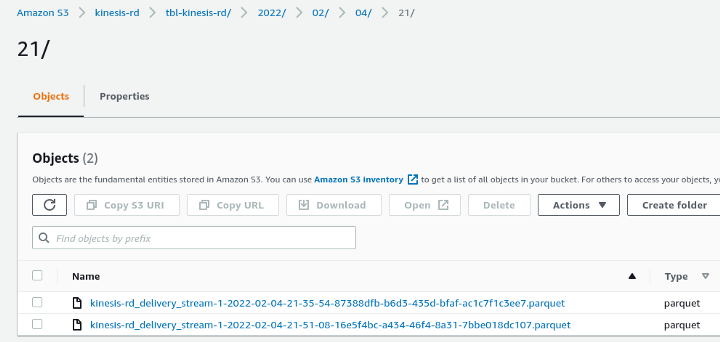
It is possible to navigate inside our S3 bucket to see how the Kinesis Data Firehose is delivering and organizing the Parquet files and creating “sub-folders” that will be recognized as partitions (year/month/day/hour — 2022/02/04/21) of our table.
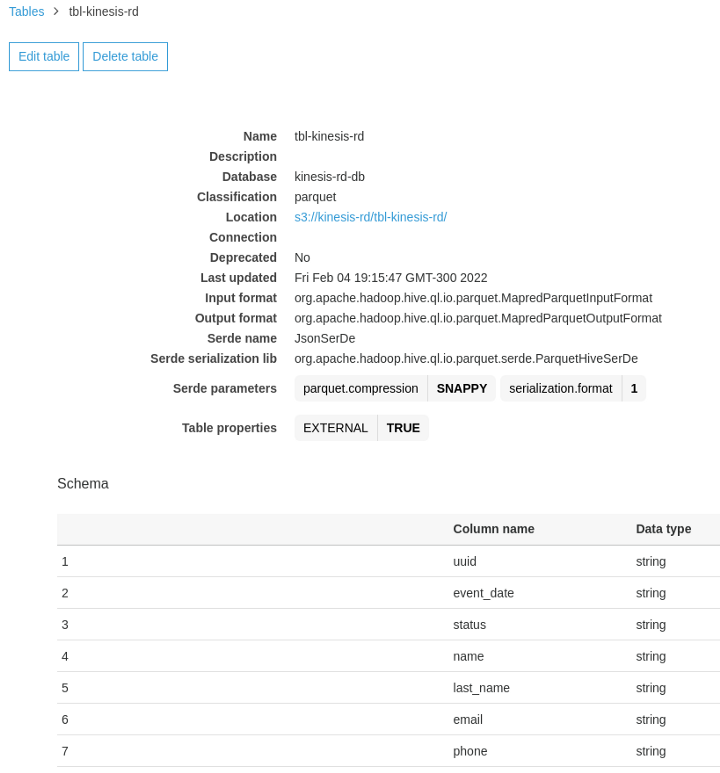
With the unified Data Catalog provided by the AWS Glue service, we are able to see the schema that was automatically identified from the messages processed by Kinesis Data Firehose.
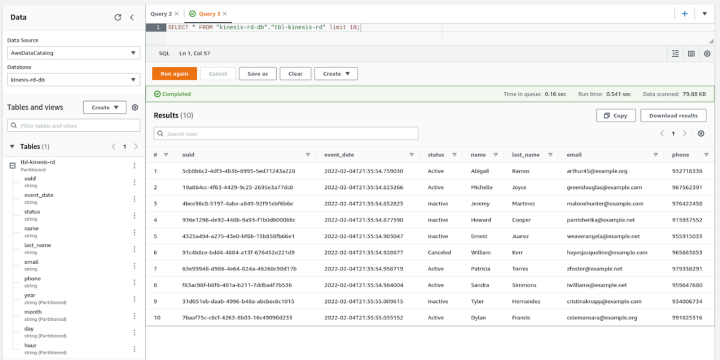
Now that our data is available and its schema is defined, we will be able to execute some SQL AdHoc queries using Amazon Athena, as shown below.
Finally, we need to destroy our infrastructure by running the command terraform destroy to avoid extra costs. Running the destroy command first asks for a confirmation and proceeds to delete the infrastructure on receiving a yes answer, as you can see in the short video below.
Conclusion
The new paradigm of the Data Lakehouse architecture is arriving to deliver more opportunities to the businesses that are planning to start their Data-Driven Journey, where now the range of technology, frameworks, and cost related to the Cloud Platform is more attractive than ever.
In this first post, we walk through one scenario of technology usage for receiving streamed data with Kinesis Data Streams, processing it in real-time using Kinesis Data Firehose, and delivering the data to object storage, where it will be available for further usage by Data Analysts, ML Engineers, running SQL AdHoc query using Amazon Athena.
In this article series on Data Lakehouses, we will take the discussion on this Architecture even further. Stay tuned!
Repository with the code used in this post.


